
Lakehouses empower teams to create diverse data products. Many persona types, as well as AI agents, operate within the lakehouse ecosystem every day.
To keep pace, your platform must remain flexible, scalable, and adaptable as data becomes increasingly democratized across the organization.
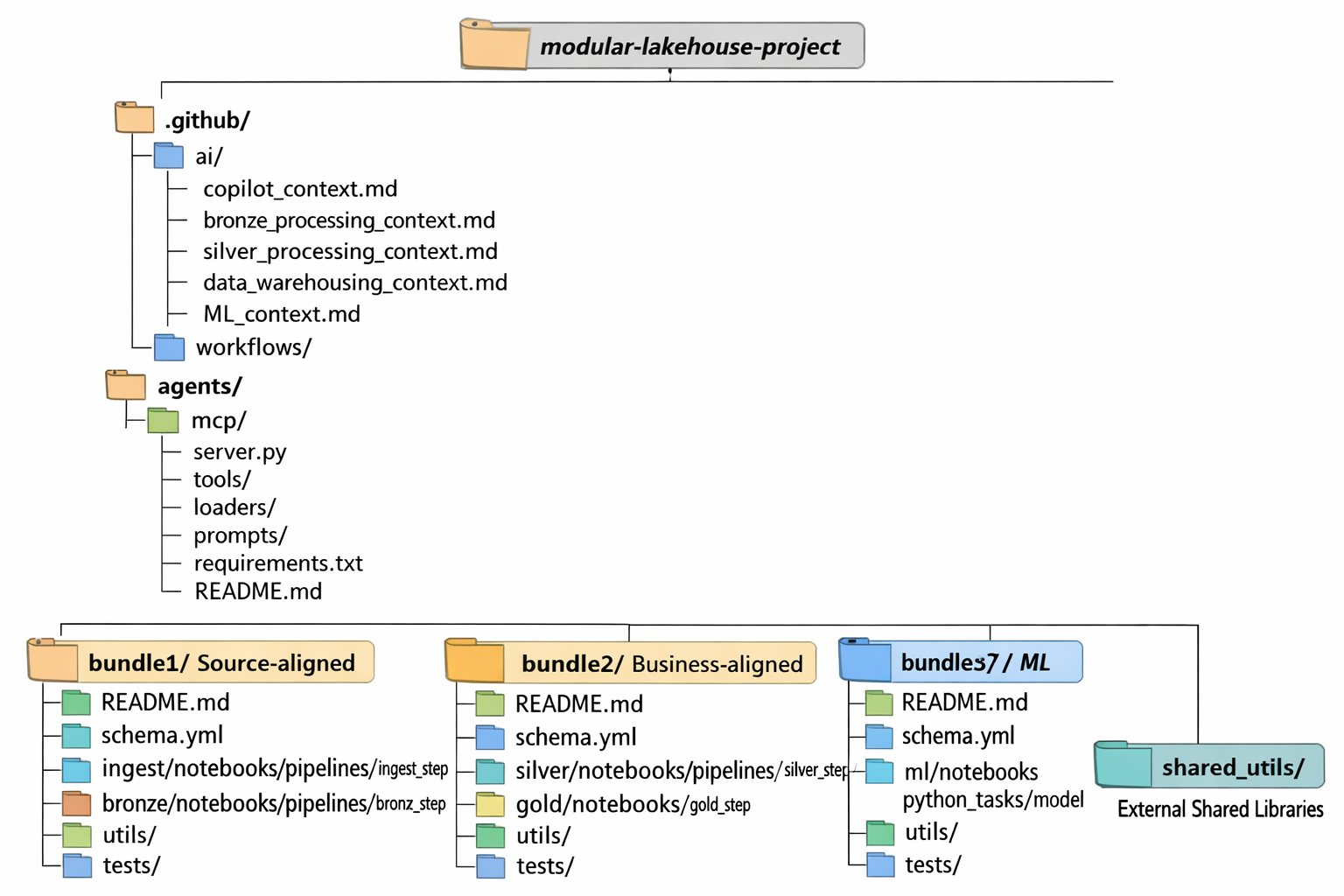
A modular design in lakehouse projects is essential. It provides a structure that supports diverse use cases and allows teams to build, extend, collaborate and innovate independently without compromising the integrity of the overall system.
When Data Platforms don’t scale organizationally
Many data platform projects start with a single purpose, but as they grow, they often turn into monoliths.
In a monolithic setup, it becomes difficult for teams to collaborate effectively and maintain clearly defined responsibilities.
In other cases, multiple independent projects with similar functionality coexist, each developed separately by different teams, leading to duplication, inefficiency, and coordination challenges.
Structure your Lakehouse around data products
To remain flexible, scalable, and future-proof, your Lakehouse should be structured around domain-aligned data products rather than technical layers.
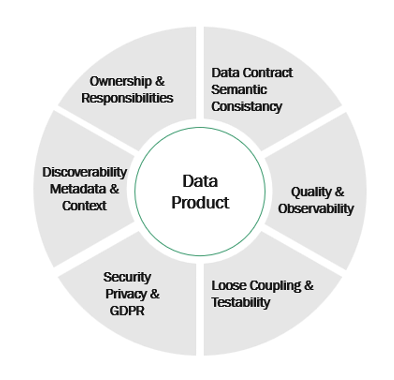
Each data product should be clearly defined and self-contained, with:
- Well-defined schemas and data contracts
- Published, discoverable outputs
- Quality expectations and observability signals
- Ownership and responsibilities
- Access controls and privacy policies
- Explicit context and instructions for AI agents
Think of each data product, a “microservice for data”: independently developed, testable, observable, and reliable, while still fitting into the broader Lakehouse ecosystem.
Independent products, but shared foundations
While data products are owned and evolved independently, they should not be built in isolation. A modular Lakehouse design relies on shared foundations that allow capabilities to be reused across product types.
By sharing core libraries across project types, the same data engineering, ML, and generative AI capabilities can support source-aligned and data warehousing products as well as ML or GenAI products without duplicating code.
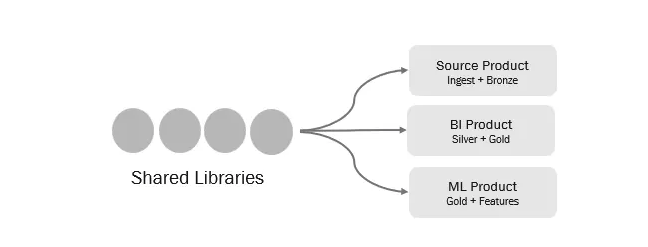
Each product consumes only the shared libraries it needs, allowing capabilities to be reused without forcing a single architecture or dependency.
This approach keeps the platform consistent while letting products move at different speeds.
A modular Lakehouse design emphasizes loose coupling and strong cohesion. Each bundle operates independently, yet collaborates through well-defined interfaces such as schemas, published outputs, and data contracts.
Coordination between data products is achieved through lightweight orchestration mechanisms, such as table triggers and event-driven patterns, rather than through hard, synchronous dependencies.
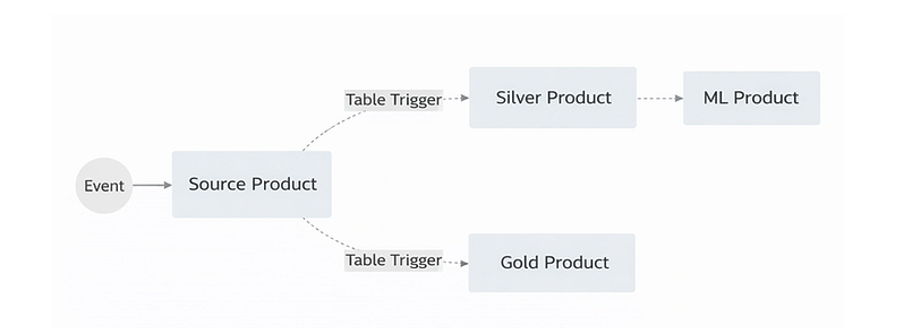
A source-aligned product focuses solely on producing data and publishing it through well-defined outputs, typically tables or events. Downstream products do not depend on the internal pipelines or execution logic of the source product. Instead, they react to data availability.
When new data arrives or a table is updated, triggers or events signal that change. These signals are used to:
- Sequence downstream execution where needed
- Initiate processing only when relevant data is ready
- Decouple execution timing from implementation details
This approach allows each product to remain autonomous. Source products can be updated, refactored, or re-deployed without coordinating changes across all consumers, as long as their published outputs remain stable.
By favoring signals over dependencies, the lakehouse supports scalable collaboration where products evolve independently while still working together as part of a coherent system.
The result is an architecture where bundles can be versioned, tested, deployed, replaced, or refactored independently, and where change is introduced incrementally rather than through large, disruptive rewrites. Reuse becomes the default, distribution scales naturally, and teams can release on their own cadence without coordination overhead.
Why modular design helps AI agents
AI agents are rapidly becoming first-class participants in the lakehouse. They are increasingly used both from IDEs such as VS Code and through online agent experiences like Agent Mode in the Databricks Assistant. In both settings, agents actively participate in data work such as planning tasks, generating code, executing workflows, and iterating on results.
Whether operating from an IDE or through online Agent Mode, AI agents rely on grounded context rather than free-form generation. Natural language prompts are interpreted through LLM-based reasoning and planning, while concrete actions are carried out through structured tool interactions such as MCP integrations, platform APIs, or other services. Throughout this process, metadata, schemas, and standards continuously guide and constrain the agent’s behavior, ensuring output remains governed, accurate, and context aware.
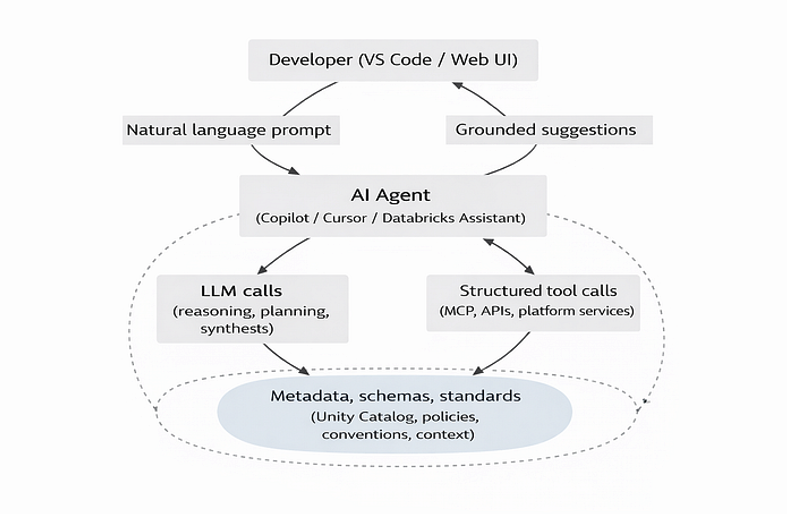
However, as agents gain autonomy, the cost of poor structure increases. Without clear boundaries, agents risk producing outputs that are technically correct but contextually misleading.
Agents don’t just need access to data. To operate safely and effectively, they require:
- Clear boundaries and responsibilities between data products
- Domain-specific context and conventions to interpret data correctly
- Governance-aware metadata to respect ownership, quality, and access controls
By organizing the Lakehouse into modular, well-documented bundles, you create an environment where AI agents can reason about data products much like human teams do, within defined scopes, guided by shared conventions, and constrained by explicit governance.
The modular design in Practice
Global AI guidance lives alongside the code, captured in dedicated contexts, defining shared standards and processing conventions. A shared MCP server may exposes platform capabilities in a controlled, reusable way. Each bundle then provides its own domain-specific context like schemas, documentation, utilities, and tests, allowing both humans and AI agents to reason locally without losing global alignment.
This is the critical point:
AI agents don’t “understand” your lakehouse implicitly. They understand what is encoded in structure, metadata, and context.
By organizing the lakehouse into modular, well-documented bundles with shared foundations and explicit AI contexts, you enable agents to move safely between IDEs, notebooks, and platform-native experiences producing results that are not only correct, but governed, explainable, and aligned with how your data products are meant to be used.
Benefits for Consumers
A modular lakehouse design does not only benefit builders, it also improves the experience for data consumers. Well-defined data products, clear ownership, and governed interfaces make data easier to discover, trust, and use.
Because schemas, metadata, and access rules are embedded into each product, data can be safely democratized across the organization without losing control. Consumers gain confidence that what they are using is accurate, current, and intended for their use case.
When combined with Genie rooms in Databricks, this structure becomes even more powerful. Genie rooms leverage lakehouse metadata and governance signals to deliver accurate, context-aware answers grounded in trusted data products. The result is consistent, traceable insights that respect ownership, quality, and access policies by default.
Built to Evolve
Modern lakehouses must support far more than data pipelines. They are living ecosystems where multiple teams, personas, and AI agents collaborate to produce, share, and consume data products at scale.
By structuring the lakehouse around modular, domain-aligned data products, organizations gain a platform that is easier to govern, safer to change, and faster to extend. Clear boundaries define responsibility, shared foundations promote reuse, and event-driven coordination enables products to evolve independently without breaking the whole.
This approach shifts the focus from managing complexity to enabling progress. Instead of slowing innovation through tight coupling or manual controls, governance and structure are built in — allowing change to happen continuously and safely.
The result is a lakehouse that doesn’t just work today, but is designed to adapt: supporting new use cases, new teams, and new AI-driven ways of working as the organization grows.