
What I like about ChatGPT is its ability to understand my natural language incredibly well: I can ask questions like: “what were the reasons for…” or “summarize top 5 risks of…” and the AI gets exactly what I mean, even if my input was unstructured, grammatically incorrect or convoluted. ChatGPT model is trained with tens of billions of inputs, so I can have a conversation about almost any topic in the world.
- talk with ChatGPT about something that is not public information – something that I have in my proprietary protected files. These are potentially my business secrets so I don’t want any leaks to the public - the generic ChatGPT model shall not gain any knowledge about my secrets!
- prevent the ChatGPT from “hallucinating” facts: I want it to strictly focus on what is contained in my data only, and honestly state “sorry I don’t know that” if it cannot find answers in my dataset.
- refer to an enormous set of information – thousands and thousands of large PDFs, data sheets, database entries and emails.
- give me a direct reference to the source of information it has used in providing an answer.
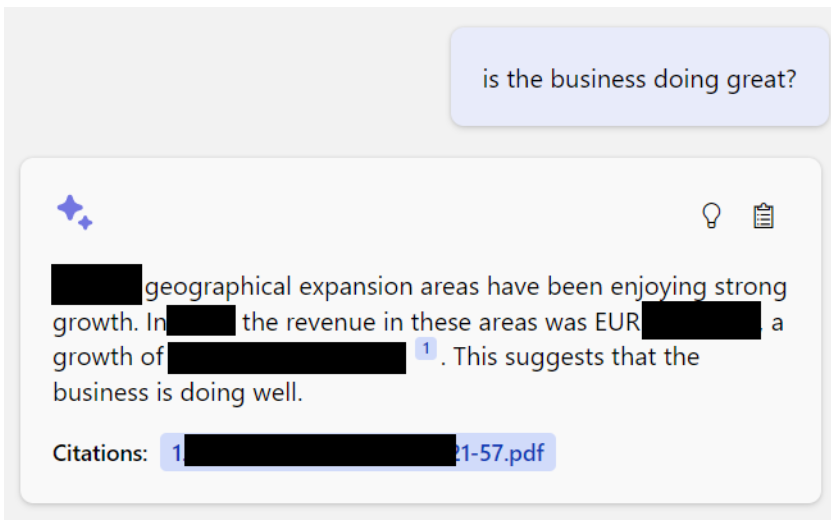
Production example: ChatGPT using my proprietary data to answer my questions.
We got access to ChatGPT API v4 in very early 2023, and ever since we were busy experimenting with it (for almost two months now). Here is our experience so far.
Disclaimer for time travelers: if you live in the future, the tech might have changed by now. This article is written in April 2023. Reader’s discretion is advised.
The naive approach
The simplest straightforward way would be incorporating all of your data directly into the ChatGPT prompt. In such cases ChatGPT can read the data together with its context and question, and respond accordingly. This technique doesn't require retraining or fine-tuning the model, and it allows for instant adaptation to alterations in the base data almost immediately.
Obviously, this introduces a new challenge: models possess a constraint on the "context length" they can accommodate (in our case we are using the GPT4 8K model, which has an 8K token context window). Even without these limitations, it would be impractical to infuse gigabytes of data into a text prompt for every interaction.
Better way
A viable solution is to store all of your data in an external knowledge base, designed to swiftly retrieve pertinent information.
This retrieval-augmented generation approach opens the door for starting simple and getting more sophisticated as needed. There are numerous possibilities for creating prompts, crafting queries for efficient extraction from the knowledge base, and coordinating the interactive exchange between ChatGPT and the knowledge base. Let’s dig into one of the potential approaches, which can be easily applied in practice.
Specific algorithm
- Ask ChatGPT itself to convert the user input (including all conversation history) into a specific query for your knowledge base.
For example, a user asks a question “which year had the highest growth in non-SaaS revenues?”. In this step the GPT model (we can use any of the GPT-3 models, like text-davinci, text-curie or other) shall receive a modified question instead, something like “I have my data stored in XYZ type of database. My user asks me ‘which year had the highest growth in non-SaaS revenues’. Please convert this question into a data query for my database”. - Use the data query from Step1 to find all the relevant information chunks in your data storage.
Here the result set will be multiple chunks of PDF sections or emails or other files that mention annual sales by revenue type. The chunks will be sorted by relevance. - Feed that (newly found) information chunks as a context to the ChatGPT and ask it to use this context in answering the original question.
In our example, the ChatGPT shall receive a modified question again, something like: “My user asks me ‘which year had the highest growth in non-SaaS revenues’. Please answer that question using the data provided below […]. Answer ‘I don’t know’ if none of the provided data has a direct answer to the user question”.
A couple of practical advices
Your data sources could be customer interaction logs, financial reports, sales data, or any other sources of structured or unstructured data. Once you have identified your data sources, the first real step is to prepare your data for a more efficient querying. This means cleaning and normalizing the data: removing any irrelevant information, converting the data into a text-based format that both data query and the Chat GPT can understand.
For example, your data might have actual conversations between real people, in either emails or instant messaging. Consider stripping away all the email signatures and formalities, i.e. “Dear Xyz, …. sincerely, John Smith” – here the greeting line and the signature are irrelevant (and actually has potential to pollute the data).
Consider splitting the data inputs. In our case we split PDF files (using pypdf library) into one-page documents, which help us to make proper citations (when ChatGPT answers the question, we ask it to provide us with the reference to the exact page, where the data was found). After that we process each page separately, extracting the text as well as tables and chunking them into separate overlapping sections. There are plenty of tools for that, in our case we utilize RecursiveCharacterTextSplitter from LangChain library.
Important design choice here is actually indexing the data. The most recommended approach will be generating, so called embeddings/vectors (for example, using OpenAI Embeddings API) to measure the text similarities and then store produced vectors within the vector stores of your choice like FAISS or Chroma or alternatively you could index the data in some other way that is more relevant for your task. Search engines like Azure Cognitive Search service, can be a viable option.
Adding a domain-relevant context for conversation
Your users will be laconic in their prompts; don’t expect ChatGPT to understand the domain from a few questions. The people will typically ask questions using as little words and characters as possible, like “which legal unit had the largest solvency risk” - they assume that the AI would know what they talk about.
We need to add the domain-relevant context to the questions, describe what model should and shouldn’t answer, and tell it how to format responses. For example, if we are creating a ChatGPT-based lawyer assistant, we shall prepend user input with an explanation, such as “You are an automated assistant to a lawyer in the Danish legal environment. Your user (the lawyer) is representing her customer in a court of arbitration. Please answer that question using the data provided below […]. Here is the question:”
Based on our experience, such conversational context makes model behavior more precise and produce more relevant answers.
Examples of usage
Hereby some of the sample conversations with our test data:
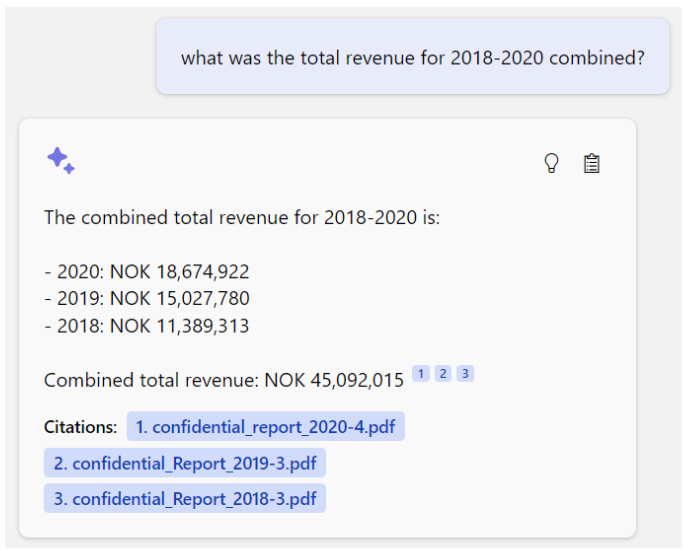
Here is another cool example. The AI perfectly understands my (flawed) question and honestly informs me about my data limitations:

Final thoughts
No AI was used in production of this article, other than the illustrations (screenshots) from our test application. The entire article was completely human-written in a classical way 🙂